
Chanho_Park
[자료구조] Python 자료구조 공부 본문
- 변수가 하나만 있을 때는 While 문 보다는 for 문
- 반복문에 하나만 반복되는 문장이 있으면 밖으로 빼준다.
- range(n) : 0 이상 n 미만인 수를 차례로 나열하는 수열
- 파이썬에서는 무시하고 싶은 값을 언더스코어로 표현 ( _ )
- if문을 반복문 밖에서 하는 게 좋다.
- 사전 판단 반복 구별하기

7. random.randint(a,b) : a이상 b 이하인 난수를 생성하여 1개를 반환

8. 데이터, 함수, 클래스, 모듈, 패키지 등을 모두 객체object로 취급
9. 객체는 자료형 data type을 가지며 메모리(저장 공간)를 차지
10. 파이썬의 변수는 값을 갖지 않는다는 특징(객체 1을 참조하는 이름에 불과) 식별변호가 바뀐다.!!!!!
11. 리터럴(literal)이란 값 자체를 의미
12. 문자 자체에 의해 값이 주어지는 문자열
(ex : 숫자 리터럴 7은 7의 값을 가지며, 문자 리터럴 CHARACTERS는 CHARACTERS의 값)
13. 배열에는 객체가 저장되며, 배열에 저장된 객체 하나하나를 원소
14. 리스트 : 원소를 변경할 수 있는 뮤터블mutable list형 객체
15. 원소에 순서를 매겨 결합한 것으로 원소를 변경할 수 없는 이뮤터블immutable 자료형

16. 슬라이스: 리스트 또는 튜플의 원소 일부를 연속해서 또는 일정한 간격으로 꺼내 새로운 리스트 또는 튜플
을 만드는 것


17. 좌변에 변수 이름이 처음 나온 경우, 그 변수에 맞는 자료형으로 자동 선언해 줍니다.
18. 대입식은 값 자체가 아니라 참조하는 객체의 식별 번호를 대입합니다.
19. 여러 변수에 여러 값을 한꺼번에 대입할 수 있습니다.
자료구조: 데이터 단위와 데이터 자체 사이의 물리적 또는 논리적인 관계
20. 자료구조를 알아야 하는 이유는 컴퓨터에서 처리해야 하는 많은 데이터를 모아 효율적으로 관리하고 구조화하는 데 있습니다.
21.
파이썬에서는 값을 비교할 때 등가성(equality)과 동일성(identity)을 사용합니다. 등가성 비교는 ==을,
동일성 비교는 is를 사용합니다.
등가성 비교는 좌변과 우변의 값이 같은지 비교하고,
동일성 비교는 값은 물론 객체의 식별 번호까지 같은지 비교합니다.
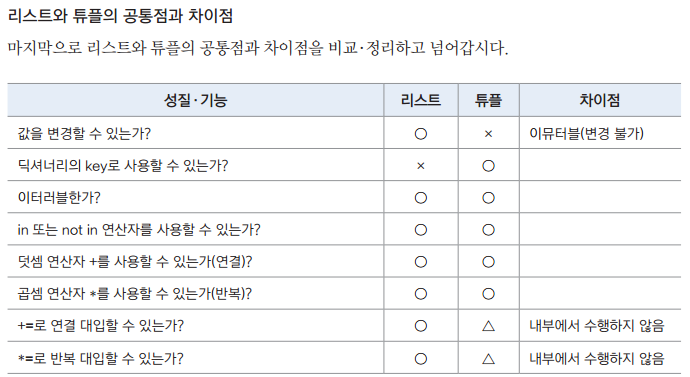
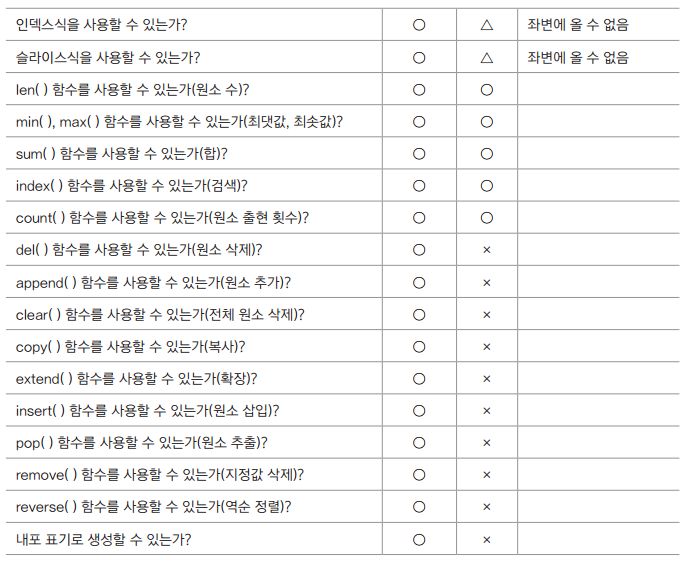
22. 내포 표기 생성? : 리스트 안에서 for, if 문을 사용하여 새로운 리스트를 생성하는 기법

모듈 : 하나의 스크립트 프로그램
이터러블 객체iterable object : 순차 반복 객체

원소를 하나씩 꺼내는 구조이며, 이터러블 객체를 내장 함수인 iter( )의 인수로 전달하면 그 객체에 대한 이터레이터iterator(반복자)를 반환
이터러블
문자열, 리스트, 튜플, 집합, 딕셔너리 등의 자료형 객체는 모두 이터러블iterable(반복 가능)하다는
공통점이 있습니다. 이터러블 객체는 원소를 하나씩 꺼내는 구조이며, 이터러블 객체를 내장 함수
인 iter( )의 인수로 전달하면 그 객체에 대한 이터레이터iterator(반복자)를 반환합니다. 이터레이터
는 데이터의 나열을 표현하는 객체입니다. 이터레이터의 __next__ 함수를 호출하거나 내장 함수인
next( ) 함수에 이터레이터를 전달하면 원소를 순차적으로 꺼낼 수 있습니다. 꺼낼 원소가 더 이상 없
는 경우에는 StopIteration으로 예외 발생을 시킵니다.
의사 코드 (pseudo code) : 컴퓨터에서 바로 실행할 수는 없지만 알고리즘을 간단하고 분명하게 나타내는 코드
x.reverse() # 리스트 x의 원소를 역순으로 정렬

기수


검색 알고리즘
주목하는 항목 = 키 ex) 국적 : 키값과 일치하도록 지정 나이로검색하는경우 나이가 키
1.배열검색

• 선형 검색(O(n)): 무작위로 늘어놓은 데이터 집합에서 검색을 수행합니다.
( 원소의 값이 정렬되지 않은 배열에서 검색할 떄 유용)
• 이진 검색( O(log n)): 일정한 규칙으로 늘어놓은 데이터 집합에서 아주 빠른 검색을 수행합니다.
• 해시법: 추가·삭제가 자주 일어나는 데이터 집합에서 아주 빠른 검색을 수행합니다.
- 체인법: 같은 해시값 데이터를 연결 리스트로 연결하는 방법입니다.
- 오픈 주소법: 데이터를 위한 해시값이 충돌할 때 재해시하는 방법입니다.
- 보초법 : 검색하고자 하는 키값을 배열의 맨끝에 저장하여 검사하는 비용을 줄임

2,연결리스트검색
3.이진검색트리검색 ( log n번)
검색 실패 : log(n+1)번
검색 성공 : log(n-1) 번
- 배열의 데이터가 정렬되어있어야함.
- 선형 검색보다 빠르게 검색
- 원소가 오름차순이나 내림차순으로 정렬된 배열에서 좀 더 효율적으로 검색할 수 있는 알고리즘
- 중앙값을 계속 찾아 줄여가는 형식
복잡도
알고리즘의 성능을 객관적으로 평가하는 기준
• 시간 복잡도(time complexity): 실행하는 데 필요한 시간을 평가합니다.
• 공간 복잡도(space complexity): 메모리(기억 공간)와 파일 공간이 얼마나 필요한지를 평가합니다.

'Study' 카테고리의 다른 글
| [Network] 네트워크 (0) | 2023.01.17 |
|---|---|
| [Ubuntu] 명령어 설치 (0) | 2023.01.12 |
| [면접예상질문] JAVA 백엔드 ,이론 기술면접 (2) | 2023.01.08 |
| [EFK] Log Aggregator란? (0) | 2023.01.07 |
| [자소서,포폴] 자기소개서,포트폴리오 정리 (0) | 2023.01.07 |